エンジニアを目指す初学者に向けて、わかりやすく解説したブログです。
最新の記事
もっとみる> 2025-04-21
nginxの運用方法(sites-available,sites-enabledの違い)
sites-avaiableは設定ファイルを配置するディレクトリ。シンボリックリンクを使ってsites-enabledに有効化したいものを配置する。
2025-04-19
SPAのここがダメ(特に初心者はやってしまいがち)
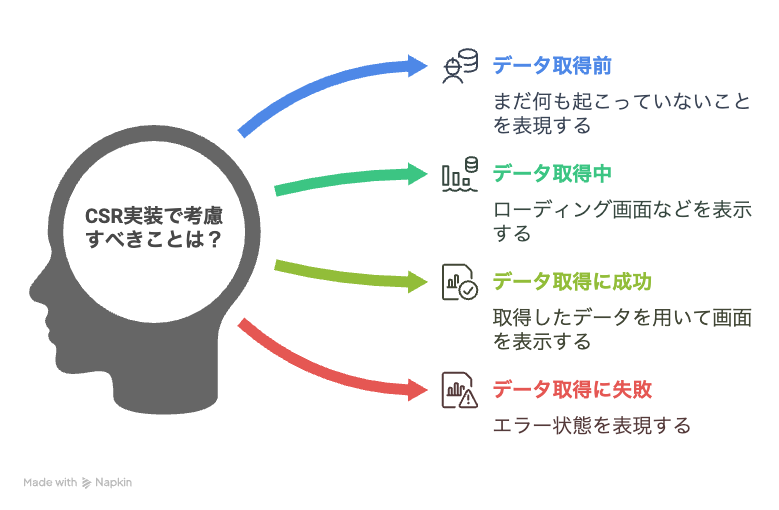
SPAは実装コストが増加し、セキュリティリスクの可能性も高まるため、そのデメリットを理解したうえで活用することをおすすめする。