プログラミング言語には、動的型付け言語と静的型付け言語の2種類が存在するが、
この記事では「静的型付け言語を使え」という話をする。
結論
- 中規模〜大規模の開発である
- チーム開発で保守をしていく
- 今は小規模でも今後成長する見込みがある
この前提条件がある場合は、迷わず型定義が使える言語を導入すべきである。
この記事では、そう判断する根拠を書く。
型定義ができる言語が良い理由6選
①コードリーディング時の認知負荷が低い
動的型付け言語に比べ、静的型付け言語はコードを読むときの認知負荷が低くなりやすい。
コードを読む際に、そのデータに関するヒントが増えるからだ。
前任者の変数名定義が多少甘かったとしても、その変数にどんなデータが入っているか想像がしやすくなる。
// 動的型付け言語(例:JavaScript)
// スコアがどんな範囲の数値を取るかを特定するには、getItemScore()を見に行く必要がある
const itemScore = getItemScore();// 静的型付け言語(例:Java)
// スコアには整数値が入ることが確定していて、小数点を伴う数値が入ることはないと断言できる
Integer itemScore = getItemScore();静的型付け言語で書くだけで、「〜かもしれない」という認知負荷を大幅に減らすことができる。
書くより読んでる時間が多くなりがちなチーム開発において
コードリーディングの認知負荷を減らしやすいのは最大のメリットだと言える。
②型関連のバグを防ぎやすい(書いている時点で気付くことができる)
動的型付け言語は、実行するまでエラーが分からない。
以下は、本来数値を入れるべき引数に文字列を入れてしまった例である。
function addScore(score1, score2) {
return score1 + score2; // 数値型を想定
}
// 実行例
const scoreA = 50;
const scoreB = "100"; // 文字列を意図せず代入
const total = addScore(scoreA, scoreB);
console.log(`Total Score: ${total}`); // 「Total Score: 50100」と出力される静的型付け言語であれば、コードを書いている途中でIDEがエラーの可能性を教えてくれる。
③実装・テストの負荷が低い
■型がないパターン
function addScore(score1, score2) {
if (typeof score1 === 'string' || score2 === 'string') {
throw new Error('エラー')
}
return score1 + score2;
} 型がないパターンで安全なテストをするには、
「score1やscore2にもし文字列が入ってしまったら?」ということを考慮に入れなければならない。
実装においても分岐が増える原因になる上に、ユニットテストでもその分だけパターンが増えてしまう。
■型があるパターン
function addScore(score1: number, score2:number):number {
return score1 + score2;
} 型があるパターンでは仕組みで文字列が入らないようになっているため、
文字列が入ってきたパターンまで考慮してテストをする必要がない。
④null関連のバグが発生しづらい
型定義がある言語はエディタがその値を解析しやすいため、ぬるぽ発生の可能性を示唆してくれる。
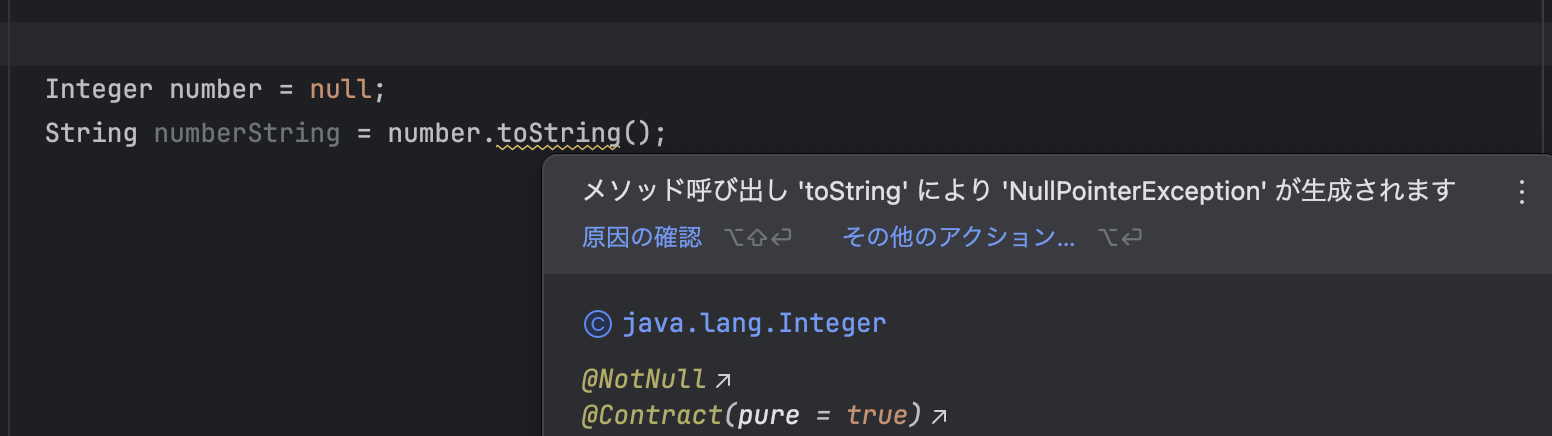

動的型付け言語に対しても多少の推論はしてくれるが、型定義が明確なときほどではない。
ビジネスロジックの実装に集中したいにも関わらず
nullやundefinedをいちいち自分で気にしながら実装しなければならないのは、本質的ではない。
⑤IDE補完やCopilotによる推測がされやすい
型定義がある言語では
「リスト系の型は.map()が使えるな」とか「文字列の型には.toUpperCase()が使えるな」などを
IDEが型から推測し、完全な補完候補を提示してくれる。
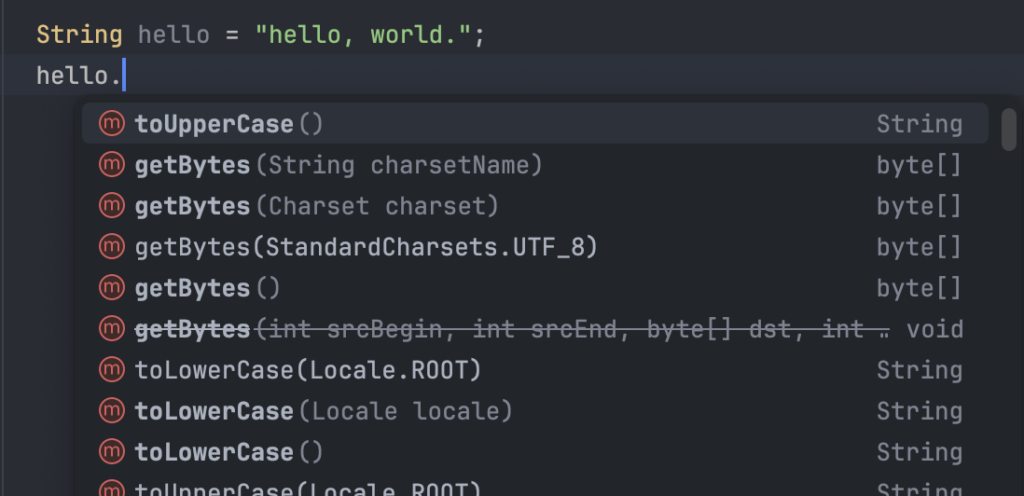
開発者としても「こういう標準メソッドが用意されているんだな」ということがすぐに分かるため
最初からドキュメントを検索する手間が省け、車輪の再開発をしてしまうリスクも低減できる。
GitHub Copilotなどのコード生成ツールにおいても
型情報があるほうがより正確なコードを推論する確率が高い。
⑥DDD(ドメイン駆動開発)との相性が良い
「読みやすいコードを設計する」という目的でよく目にするのがDDDである。
DDDは型定義ができる言語において本領を発揮する開発方法のため、
DDDを意識した書き方をしたい場合は静的型付け言語を選定しておいた方が良い。
細かくは触れないが①の例では、次のように書くことができる。
// Javaの例
// ItemScoreには仕様が明記されており、実装を見ると「1~100の値を取る」などがわかるようになっている
ItemScore itemScore = getItemScore();逆に、動的型付け言語が優れている点
ここまで「静的型付け言語の方が素晴らしい」ということを言ってきたが
もちろん動的型付け言語が優れている点も存在する。
それは「型を気にしなくて良いので開発スピードが速い」ということである。
そのため、前提条件にも記載したことではあるが
- 個人開発
- 小規模
- 保守運用する予定がない(2度と読むことがない)
というケースにおいては、動的型付け言語で実装したほうが楽と言えるだろう。
ただし、最近はGitHub Copilotなどのコード生成ツールが生まれたことで
その「実装の速さ」というメリットは失われつつあると筆者は考えている。
まとめ
どちらの言語も書いたことがある身としては、結局型定義ある方が実装が早いと感じる。
その理由としては、今回挙げた理由を根拠にした「手戻りの少なさ」だ。
「会社のプロダクトに型定義を導入しました!」という技術記事を見るたびに
先人の苦労を糧に、自分たちは同じところで苦労しないように進めたいと強く思う。
ぜひこれから技術選定を行う人がいたら、積極的に型が使える技術選定や環境を整えていただきたい。
余談
動的型付け言語のメリットとして「記述の柔軟性」というメリットを挙げている記事を見かけるが
これが全く理解できていないので、分かる人が居たら教えてほしい。
筆者はコード変更時の「変更しやすい」という意味だと捉えたが
変更しやすいかどうかはコード設計の方が大きく影響があると思っているので
この説明では納得がいかない。
もう一つの可能性として「異種データを同様に扱うことができる」という主張であれば
それはバグの温床なのでやめた方が良いし、interfaceのような抽象化の仕組みを使うことで十分解決できる。
